Axiome Research
A pre-registered, confounder-aware study in software code review — and why the same structure governs financial markets.
Why this is here
Axiome is built on a single claim: artificial intelligence cannot predict the output of a process that has no stable ground truth. Market prices are the canonical example. They are not measurements of reality — they are the aggregate of every participant's attempt to predict every other participant. A model trained on that data converges to a consensus that is, by definition, already priced in.
If that claim held only for markets, it would be an observation about finance. It is not. The same structure appears wherever an outcome is a collective judgment rather than a fact. The study summarized here demonstrates it — adversarially, and under pre-registration so the conclusion could not be reverse-engineered from the result — in a domain with no connection to markets at all: the review of software code.
The question
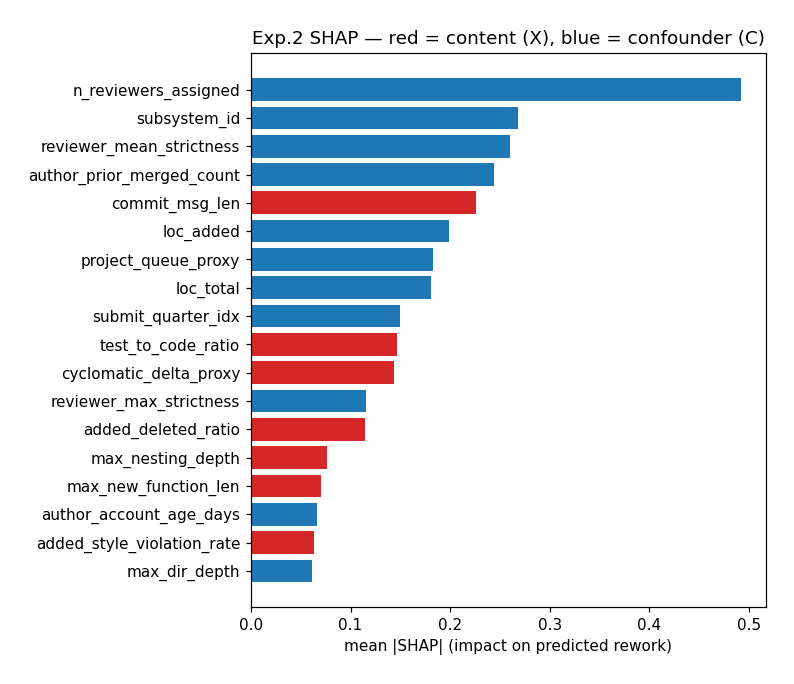
Automated coding agents differ in cost by more than an order of magnitude. The obvious way to save money is to route cheap agents to easy work and expensive ones to hard work — which requires a predictor: given the content of a proposed change, will a team accept it, or send it back for costly rework? Crucially, for that prediction to have any routing value, its power must come from the content. It cannot come from who authored the change, who reviews it, how large it is, or which part of the system it touches — a router writes a diff; it cannot change any of those things.
The study asked, directly and adversarially, whether that content signal exists — and fixed every decision threshold in advance, so that a negative result could not later be reinterpreted as a success.
The finding
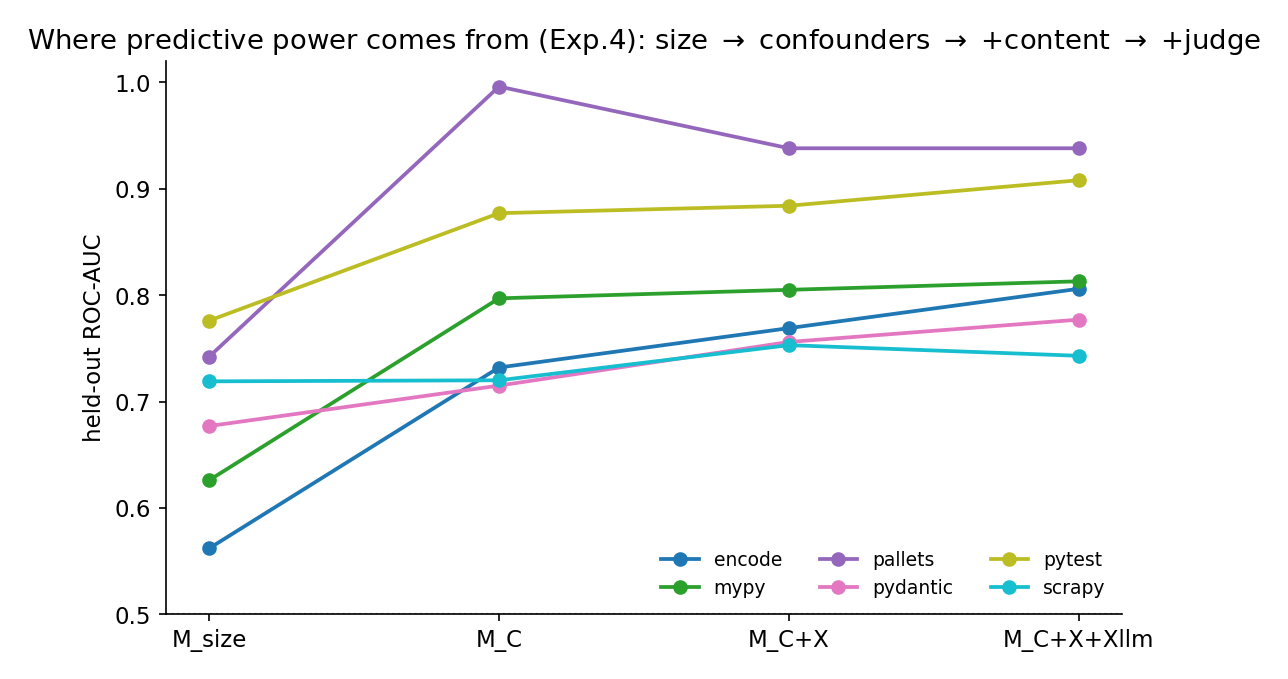
A single, robust structure emerged across all five phases of the study. The decision to accept a change decomposes into two components that point in opposite directions.
Will this specific change clear the bar?
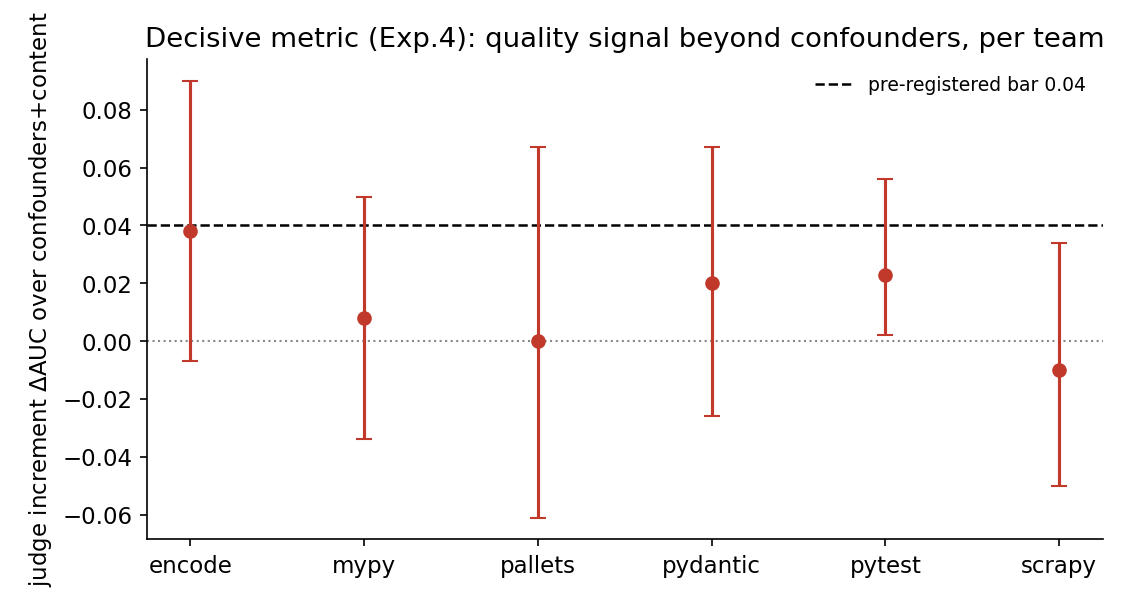
Governed almost entirely by context a router cannot move — author, reviewer, size, subsystem. Beyond those confounders, the content of the code adds essentially nothing.
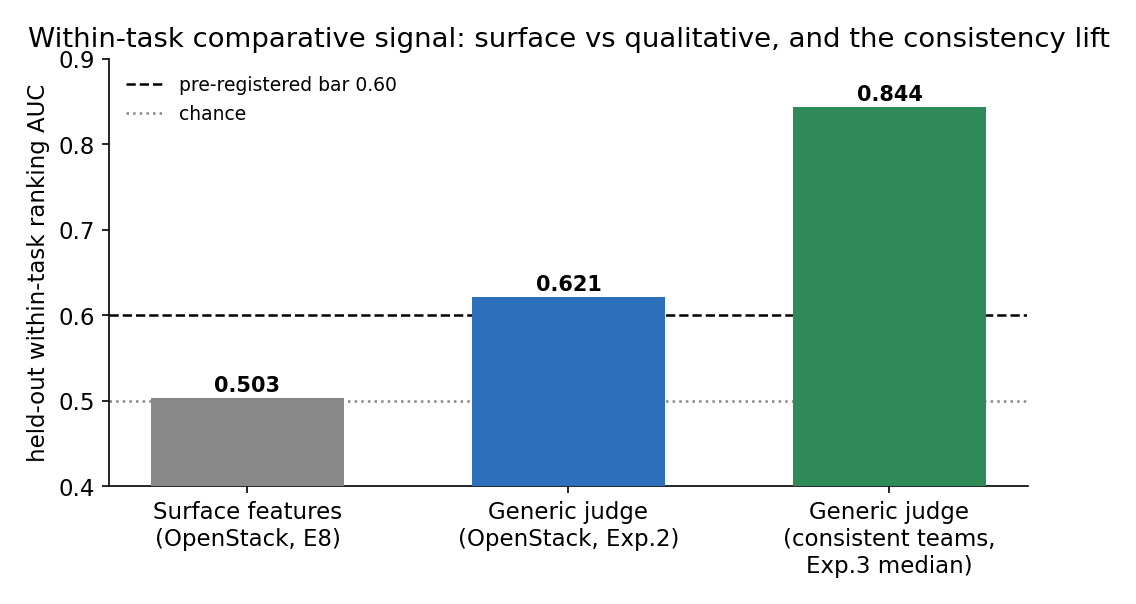
Which of two solutions to one task is better?
Carries a real, if modest, signal — stronger in consistent teams. But it is largely shared across teams, and never converts into the absolute prediction routing requires.
A router lives entirely in the absolute world: it must decide whether one cheaper output is acceptable, not merely rank two outputs it has already paid to generate. And in the absolute world, the signal is not there. What is predictable — who, how big, which area — is exactly the part no model can act on. The predictable and the actionable are disjoint.
Why the result holds
The finding is structural, not a feature-engineering shortfall. Three properties rule out "better features would have found it": two independent statistical routes converge on the same null, the null reappears against a clean defect oracle and a strong quality judge, and it survives the two settings most favorable to a content signal — within-task comparison and per-team training.
The bridge to markets
Code review and markets share no mechanics, yet they share a structure. Both are consensus- and identity-driven processes whose output is a judgment produced by interacting participants. In both, the study's phrasing applies exactly:
"A process whose output is a judgment produced by interacting participants, in which the content of the judged object explains far less of the outcome than the identities and efforts of the judges."
That is the market thesis, restated in another field. Prices aggregate disagreement; acceptance aggregates reviewers. In each case a model trained on the historical record can reach real accuracy — but that accuracy is carried by structure it cannot act on, while the part it could act on carries no signal.
The constructive response is the one Axiome is built on: operate only where ground truth is automatic — questions with stable, verifiable answers — and never ask a model to infer a signal from a process that does not contain one. It is the same line that separates a profitable system from an expensive one, drawn here in a second domain.
See what this principle produces when AI and systematic methods each do only what they are suited for.
Explore the Market Study →